Платформа раннего прогнозирование аварий
На площадке DSP, где идут аукционы в реальном времени, мы заметили странный паттерн: в пике один из крупных участников торгов перестаёт слать биды, а нагрузка на инфраструктуру не падает — наоборот, растёт.
Гипотеза
Если участник «выпадает» не полностью, а остаётся полуактивным (таймауты, ретраи), остальные узлы получают больше повторных запросов и хуже отрабатывают дедлайны аукциона. Система становится нежизнеспособной не от абсолютного QPS, а от перераспределения нагрузки.
Я сформулировал гипотезу, согласовал с платформенной командой, провёл контролируемый эксперимент на стейдже: искусственно урезали долю бидов одного sandbox-участника. Картина совпала с прод-инцидентом неделей ранее.
Решение
Написал отдельный сервис на FastAPI:
- стрим метрик из Kafka (bid rate, timeout rate, p99 latency по participant_id);
- скользящее окно и z-score по отклонению от базовой линии;
- алерт в Slack и webhook в оркестратор, если порог держится 3–5 минут;
- горизонт предупреждения — до 15 минут до прогнозируемого отказа по эвристике «тренд + запас по CPU».
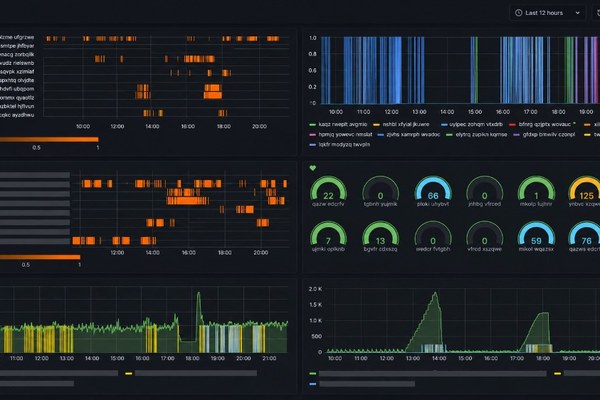
На дашборде (фрагмент на промо-картинке) видно те же всплески, которые раньше замечали постфактум: резкий пик около 18:30, потом откат. Теперь такой пик сопровождается тикетом до того, как дежурный открывает Grafana сам.
Итог
Детектор не чинит торги — он даёт время переключить флаги, ограничить fan-out, позвонить партнёру. Главный урок: в RTB сначала проверяй гипотезу измерением, потом пиши код. Иначе получишь красивый микросервис, который алертит на шум.